上一节我们提到,编程语言里的各种符号都是与计算机底层数字电路的一种约定,这也是程序员编写的代码能够控制计算机工作的原因。对于设计架构好的计算机而言,以add命令为例,什么样的外在表现(比如产生一组数字电信号 0x83)能够使得计算机做一次 add 运算,我们就将什么外在表现定义为 add。

本例是约定 0x83 为
add指令,之后,只要在输入设备输入 0x83 就能够产生的add指令对应的数字电信号序列,这样,计算机就可以执行add计算了。
所以,当计算机的架构改变后(例如cpu的电路设计改变),它的指令集通常也会变化(比如上面的add指令不是0x83了)。那么,同样一项业务,在不同架构的计算机上就得写不同的代码吗?这岂不是太麻烦了。的确,在机器码和汇编编程时代,这真的是个大问题,好在之后人们设计出了 C 语言,在一定程度上解决了这个问题:C语言代码具有可移植性,只需少量修改甚至不用修改,就能在不同架构上的计算机运行。

程序员们习惯称机器码和汇编语言为低级语言,C,c++等编程语言为高级语言。
C语言代码的可移植性能力其实归功于编译器,我们看下面这张图:

这是使用机器语言,汇编语言和C语言实现同一个功能的代码对比。因为汇编代码只是用较易记的符号代替机器语言的功能码,所以汇编代码和机器语言代码是一一对应的,从汇编语言代码到机器语言代码也只需简单替换即可。C语言代码就不一样了,它的一行语句,汇编语言需要使用3行来解释。上一节我们提到,计算机只能认识数字,所以C语言代码它是执行不了的,将 C 语言代码翻译为机器码是必须的。这里说的翻译,就是编译器的工作,编译器将高级语言代码翻译为计算机认识的机器码。
这就好理解为什么 C 语言能够较轻易的跨平台运行了:只要提供不同架构的计算机对应的编译器就可以了,编译器能够自动的将C语言代码翻译为指定架构的机器码。而一份编译器能够使用任意多次,所以这么做是非常划算的。

通过上面的例子,我们知道通常一行C语言代码,需要若干行机器码解释。一转多,就有很多可能性了,可能又N种转换方法能够完成工作,但是效率却可能大大不同。所以,编译器的优化对提升最终的运行效率而言非常关键。现在的编译器通常都优化的很好,请看下面这几句代码:
#include <stdio.h>
int main()
{
int a;
a = 1;
a = 2;
if(0==1)
a = 1+2;
return 0;
}
我们申请了一个 int 型的变量 a,然后分别赋值两次。但是对编译器而言,它可能会认为这几句代码什么也没做,因为你给 a 赋值,但是并没有使用 a 啊,所以它编译时,就认为你什么都没做,编译时,直接就将这两句忽略掉了。对于上面的 if 语句,因为 0 永远不可能等于 1,所以,编译器会认为这个 if 也是没有任何作用的,编译时,也就忽略它了。
我们编译它,然后查看编译后的汇编代码:
$ gcc -O2 t.c -g
$ objdump -dS a.out
a.out: file format elf64-x86-64
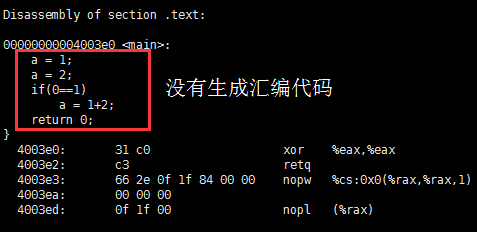
可以看出,最终生成的可执行文件,上面的代码实例中的 a 的两句赋值,和 if 判断被编译器判定没有意义,因此没有生成任何汇编代码。编译器认为没有的事情就不要做,以此提升效率。但是,在使用 C 语言操纵硬件,a 表示寄存器时,即使只是对 a 赋值也是非常有意义的,那编译器这么做不就出错了吗?事实的确如此,所以在 C99 标准中有 “volatile”关键字,就是专门解决这种问题的。下一节,我们再一起讨论一下“volatile”这个关键字。

欢迎在评论区一起讨论,质疑。文章都是手打原创,喜欢我的文章就关注一波吧。